IPAmj明朝フォント
先日、IPA から IPAmj明朝フォントの正式版が公開された。
情報処理推進機構:プレス発表:記事:行政機関向け文字情報基盤の公開について
目的は行政機関での文字統一化が図ることにあるようで、やっと、という感も
するのだけど、とりあえずダウンロードして使ってみることにした。個人的には
明朝体ではなく楷書体を出して欲しい気がしたのだけど、お役所じゃ使わないの
でしょうから期待するのが間違いかもしれない。
辺の異体字
impress のページにある感じで、渡辺とか川辺とかの。
http://internet.watch.impress.co.jp/docs/news/20111027_486475.html
辺の異体字を調べてみた。素人なので、異体字と俗字の違いもわかってないけど。
| 字 | MJ文字
図形名 | X0213 | 対応UCS
|
|---|
 | MJ025757 | | U+8FB9
|  | MJ025758 | 1-42-53 | U+8FBA
|  | MJ025759 | 1-42-53 | U+8FBA
|  | MJ026190 | 1-78-21 | U+9089
|  | MJ026191 | 1-78-21 | U+9089
|  | MJ026192 | 1-78-21 | U+9089
|  | MJ026193 | 1-78-21 | U+9089
|  | MJ026194 | 1-78-21 | U+9089
|  | MJ026195 | 1-78-21 | U+9089
|  | MJ026196 | | U+9089
|  | MJ026197 | | U+9089
|  | MJ026199 | 1-78-20 | U+908A
|  | MJ026200 | 1-78-20 | U+908A
|  | MJ026201 | | U+908A
|  | MJ026202 | | U+908A
|  | MJ026203 | | U+908A
|  | MJ026204 | | U+908A
|  | MJ026205 | | U+908A
|  | MJ026206 | 1-78-20 | U+908A
|  | MJ026207 | | U+908A
|  | MJ044966 | | U+26347
|  | MJ050872 | | U+284C9
|  | MJ050883 | | U+284D9
|  | MJ051123 | | U+28622
|  | MJ051124 | | U+28622
|  | MJ058859 | | U+28559
|  | MJ058864 | |
|  | MJ058866 | | U+9089
|  | MJ058869 | | U+2B7EA
|  | MJ058870 | | U+908A
|  | MJ060232 | |
|  | MJ060234 | | U+9089
|  | MJ060235 | | U+9089
|  | MJ060236 | | U+9089
|  | MJ060237 | | U+9089
|  | MJ060238 | | U+9089
|  | MJ060239 | | U+9089
|  | MJ060240 | | U+908A
|  | MJ060241 | |
|  | MJ060242 | |
|  | MJ060243 | |
|  | MJ060246 | |
|  | MJ060248 | | U+9089
|  | MJ060249 | |
| |
44文字あった。実際の戸籍から参照してる(?)のだろうから、ここに含まている
漢字でほぼ人名が網羅されているのだろうか。最近では、面倒だから略字に変更
したなんて話も聞くけど。
イースト株式会社が発売している「人名外字PROV4」という製品がある。
http://www.est.co.jp/fe/jmpro/index.html
この中には、辺の異体字は65文字収録されている、とある。JIS にある3文字を
含めると、68文字になる。
http://www.est.co.jp/fe/jinmei/sw_itaiji.htm
漢字の収録が多いらしい「超漢字」を出しているパーソナルメディア株式会社は
「超漢字検索」という Windows 上でも動作するアプリを出している。10日間の
試用ができるみたいなので、ダウンロードして使ってみた。
http://www.chokanji.com/ckk/
| 字 | GT
フォント | TRON
コード
|
|---|
 | GT36596 | 2-A0A7
| 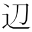 | GT51654 | 3-435A
| 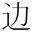 | GT51655 | 3-435B
| 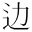 | GT51686 | 3-437A
| 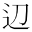 | GT51687 | 3-437B
|  | GT52035 | 3-475F
|  | GT52036 | 3-4760
|  | GT52154 | 3-4878
|  | GT52155 | 3-4879
|  | GT52284 | 3-4A3E
|  | GT52397 | 3-4B51
|  | GT52660 | 3-4E3E
|  | GT52725 | 3-4F21
|  | GT52726 | 3-4F22
|  | GT52765 | 3-4F49
|  | GT52766 | 3-4F4A
|  | GT52767 | 3-4F4B
|  | GT52803 | 3-4F6F
|  | GT52804 | 3-4F70
|  | GT69518 | 3-24BB
|  | GT69519 | 3-24BC
|  | GT71831 | 3-36E8
|  | GT71834 | 3-36EB
|  | GT71835 | 3-36EC
|  | GT71840 | 3-36F1
|  | GT71841 | 3-36F2
|  | GT71843 | 3-36F4
|  | GT71844 | 3-36F5
|  | GT71845 | 3-36F6
|  | GT71846 | 3-36F7
|  | GT71848 | 3-36F9
|  | GT71849 | 3-36FA
|  | GT71850 | 3-36FB
|  | GT71851 | 3-36FC
|  | GT71852 | 3-36FD
|  | GT71853 | 3-3780
|  | GT71854 | 3-3781
|  | GT71855 | 3-3782
|  | GT71856 | 3-3783
|  | GT71857 | 3-3784
|  | GT71858 | 3-3785
|  | GT71859 | 3-3786
|  | GT71860 | 3-3787
|  | GT71861 | 3-3788
|  | GT71862 | 3-3789
|  | GT71863 | 3-378A
|  | GT71864 | 3-378B
|  | GT71865 | 3-378C
|  | GT71866 | 3-378D
|  | GT71867 | 3-378E
|  | GT71868 | 3-378F
|  | GT71869 | 3-3790
|  | GT74234 | 3-49F1
|  | GT74236 | 3-49F3
|  | GT74237 | 3-49F4
|  | GT74238 | 3-49F5
|  | GT74240 | 3-49F7
|  | GT74241 | 3-49F8
|  | GT74243 | 3-49FA
|  | GT77663 | 3-658E
|  | GT77664 | 3-658F
|  | GT77665 | 3-6590
|  | GT77668 | 3-6593
|  | GT77673 | 3-6598
|  | GT77674 | 3-6599
|  | GT77675 | 3-659A
|  | GT77676 | 3-659B
|  | GT77679 | 3-659E
|  | GT77682 | 3-65A1
|  | GT77686 | 3-65A5
|  | GT77687 | 3-65A6
|  | GT77688 | 3-65A7
|  | GT77689 | 3-65A8
|  | GT77690 | 3-65A9
|  | GT77693 | 3-65AC
|  | GT77695 | 3-65AE
|  | GT77698 | 3-65B1
|  | GT78530 | 3-6BFD
|  | GT78556 | 3-6C99
|  | GT78557 | 3-6C9A
|  | GT78578 | 3-6CAF
|  | GT78579 | 3-6CB0
|  | GT78587 | 3-6CB8
|  | GT78588 | 3-6CB9
|  | GT78589 | 3-6CBA
|  | GT78597 | 3-6CC2
|  | GT78604 | 3-6CC9
|  | GT78608 | 3-6CCD
|  | GT78609 | 3-6CCE
|  | GT78610 | 3-6CCF
|  | GT78611 | 3-6CD0
|  | GT78612 | 3-6CD1
|  | GT78613 | 3-6CD2
|  | GT78614 | 3-6CD3
|  | GT78615 | 3-6CD4
|  | GT78624 | 3-6CDD
|  | GT78625 | 3-6CDE
|  | GT78627 | 3-6CE0
|  | GT78628 | 3-6CE1
|  | GT78629 | 3-6CE2
|  | GT78635 | 3-6CE8
|  | GT78636 | 3-6CE9
|  | GT78637 | 3-6CEA
|  | GT78638 | 3-6CEB
|  | GT78639 | 3-6CEC
|  | GT78640 | 3-6CED
|  | GT78641 | 3-6CEE
|  | GT78642 | 3-6CEF
|  | GT78643 | 3-6CF0
|  | GT78644 | 3-6CF1
|  | GT78645 | 3-6CF2
|  | GT78646 | 3-6CF3
|  | GT78666 | 3-6D89
|  | GT78669 | 3-6D8C
|  | GT78670 | 3-6D8D
|  | GT78671 | 3-6D8E
|  | GT78672 | 3-6D8F
|  | GT78673 | 3-6D90
|  | GT78674 | 3-6D91
|  | GT78675 | 3-6D92
|  | GT78676 | 3-6D93
|  | GT78677 | 3-6D94
|  | GT78678 | 3-6D95
|  | GT78679 | 3-6D96
|  | GT78690 | 3-6DA1
|  | GT78694 | 3-6DA5
|  | GT78701 | 3-6DAC
| |
3倍近くの127文字あった。この数字だけを見ると、IPA のフォントはまだまだ
かな、と思ってしまう。必要性の面からどうなのか、というのは現場の人じゃ
ないとわからないけど。現場じゃ、渡辺の辺を出すだけで、大変なのかな。
斉の異体字
impress のページで、検証版のときには、
http://internet.watch.impress.co.jp/docs/news/20110518_446606.html
斉の異体字だったので、ついでに調べてみようと思った。しかし、思った以上に
「辺」の異体字に時間がかかってしまったので、また何かの機会があったときに
調べることに。
どちらの文字にしても異体字が多いのは、名前に使われているからだと思う。
名前に使われていなければ、略字にしたところで大きな問題は起きないだろう
ことだろうし。
実際の入力とか
結局のところ、入力方法と保存形式が確立されていないと、使うにも使えない
状況になる。UTF-8 や Shift-JIS や EUC に乗せられるかという問題があるし、
受け取る側も表示するためのフォントが入っている必要もあるし。渡辺と変換
したいのに、候補が100も出てきたら操作性が落ちてしまうし。
なんだか、ほんのちょっとの違いが重要なのだけど、数十文字しかない欧米の
文化圏から見ると異質な感じだろうな、と思ってしまう。
実際の役所での戸籍課なんかでは、これまで外字を作成して対応をしてきた、
という話を聞くと、勝手に文字を作って届出してしまえば、作ってくれそうな
気もしないことないけど。この辺り、祖先が使っていた文書なんかを提出して
初めて認められるのかもしれないけど、どうなんだろう。
ところで
この IPA フォントを作るのに、かなりの税金が使われたと予想する。各機関との
調整は良いとして、異体字の選定とかフォントの作成とかで。超漢字なんかでも
使っているGTフォントはパーソナルメディア株式会社を離れ、今は東京大学の
多国語処理研究会が扱っているようである。せっかくの文字数を扱えるのだから、
これを利用すれば良かったのに、と単純に思ってしまう。ライセンスとか、他の
障害が裏にあるのかもしれないし、実際に利用しているのかもしれないけど。
何というか、コンピュータが普及して10年以上経って、まだ自分の苗字を簡単に
表示できない人がいると思うと、不思議な感じがする。
|